Motivation
In our previous posts, we did not talk much about compilation time overhead. For long running or precompiled queries, that makes sense, as the compilation time would be negligible compared to the running time. However, for prototyping or quick jobs, it may become quite important.
Let’s take a look at a small example with the famous tpch 6 query:
scala> val tpchq6 = """
select
sum(l_extendedprice*l_discount) as revenue
from
lineitem
where
l_shipdate >= to_date('1994-01-01')
and l_shipdate < to_date('1995-01-01')
and l_discount between 0.05 and 0.07
and l_quantity < 24
"""
Once the code is generated, the compilation time using GCC at optimization level of 3 is 97ms, while the running time of the compile code is 73ms on a dataset of 100MB. The following graphs show the compilation and running times for different compiler configurations.
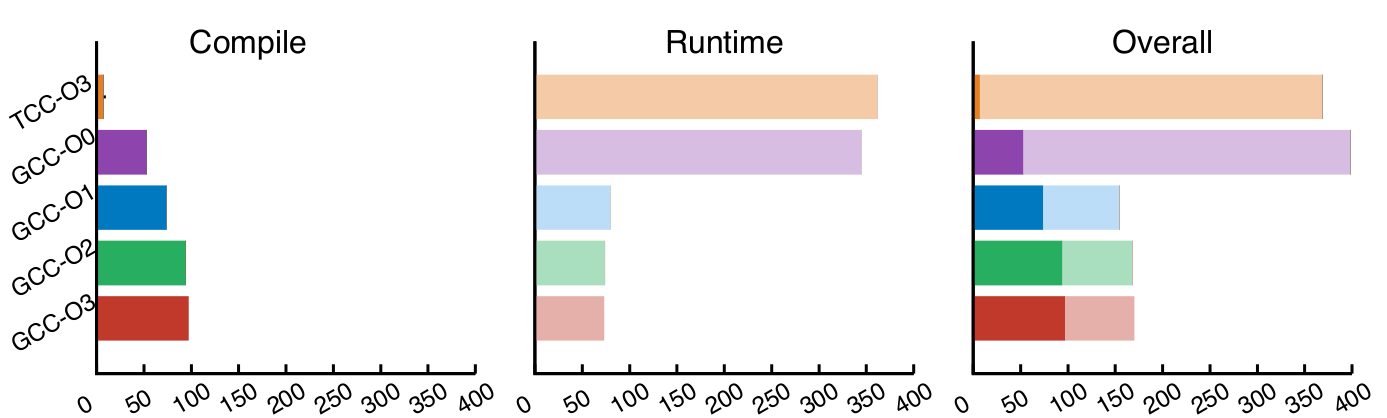
The first result that stands out is the fact that GCC with a higher optimization setting, while having a slightly lower runtime, has a much higher compilation time. This indicates that in a dynamic setting, the highest optimizations may not always be the best choice. We also see that some compilers (in our case, TCC) have a very quick compilation time, while lacking the performance at runtime.
However, we see here an opportunity: what if while GCC compiles the code with the highest optimization setting, we start running the query using the code generated by TCC? Then, using on stack replacement technique (OSR), we can swap to the GCC compiled code when available. Any initializations/computations made would be a bonus!
Let’s Explore Deeper
In order to get that bonus, let’s look at the kind of code that we would like to generate. We won’t give all the details but rather give a general idea of what we would expect to see. From what we discussed in previous post, a basic aggregate in Flare would be generated as:
double res = 0;
for (int i = 0 ; i < n; ++i) {
res += a[i] * b[i];
}
printf("%.4f\n", res);
And a join would look like:
int next
int* key = malloc(...);
... // hash map data structure
for (int i = 0 ; i < n; ++i) {
key[next] = ...; // insert to hash map
}
for (int i = 0 ; i < m; ++i) {
int* match = ...; // get data from hash map
while (match != NULL) {
if (...) { // join condition
printf(...); // print tuple
}
match = ... // iterate through match
}
}
We see that in the case of Flare (and all databases following the datacentric model), the code generated is mainly composed of big loops iterating through tables and processing tuples one at a time. We see here an opportunity to have a clean way to swap between the compiled codes. Instead of supporting general OSR, i.e., being able to jump at any point in the program, we generate code that can easily swap after each loop iteration. Taking our aggregate example, let’s split it in two compilation units that would look like:
Compilation unit 1 (aggregate.c):
extern volatile int loaded; // will be set to 1 when the new code is loaded
int aggregate_loop(double* res_p, int* i_p, int n, double* a, double* b) {
double res = *res_p;
int i = *i_p;
while (i < n) {
#ifdef CAN_SWITCH // we only check for loaded if another version is going to be compiled
if (loaded) {
*res_p = res;
*i_p = i;
return NOT_DONE;
}
#endif
res += a[i] * b[i];
}
*res_p = res;
return DONE;
}
Compilation unit 2 (main.c):
extern fun_ptr loaded_fun; // pointer to loaded function
double res = 0;
int i = 0;
if (aggregate_loop(&res, &i, n, a, b) != DONE) {
loaded_fun(&res, &i, n, a, b);
}
printf("%.4f\n", res);
The first compilation unit can be compiled with GCC and TCC, and swap when the new code has been loaded. In order to load the code, we can an auxiliary thread such as:
volatile int loaded;
fun_ptr loaded_fun;
void* load_shared(void* args) { // launched as a separate thread
// Wait for a region to be compiled.
char trash[2];
int nc = read(0, &thrash, 2); // the process compiling with GCC will notify on stdin
void* plugin = dlopen("library.so");
loaded_fun = dlsym(plugin, "aggregate_loop");
if (loaded_fun == NULL) return NULL;
loaded = 1;
return NULL;
}
Running the Code
Now, we need to launch the different compilation and computation processes. The GCC compilation process will have to notify the other process that it is done; a solution is to send a single character on standard input.
function compile_gcc() {
gcc -O3 -shared -fPIC -o library.so aggregate.c
echo -n 0
}
function compile_and_run_tcc() {
tcc -o query main.c aggregate.c -DCAN_SWITCH -lpthread -ldl
}
compile_gcc | compile_and_run_tcc
Results
We modified Flare in order to generate code that supports OSR at the loop iteration level. Let’s see how our star query is doing on different compiler configurations:
On 100MB:
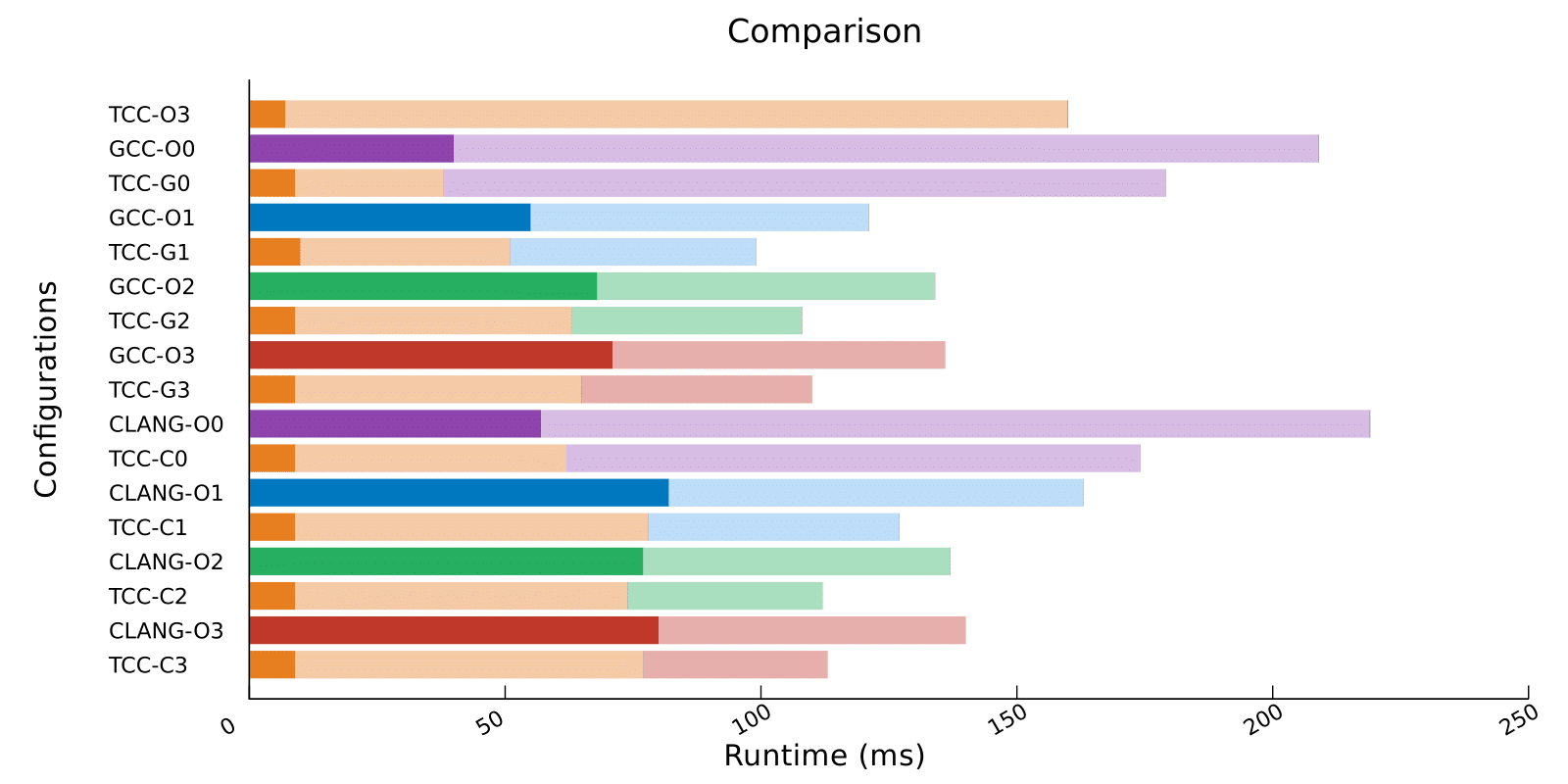
We have seen that the fastest configuration without OSR was compilation with GCC using -O1. We always use TCC for the fast start up, as using GCC with -O0 doesn’t make sense due to the fact that the generated code is as bad as the one generated by TCC, while taking much longer to compile (see previous graph).
When the second compiler is GCC with flag -O1, we see a 20% speedup. With -O2 and -O3 the speedup is only 10%. With Clang as a second compiler, -O2 and -O3 behave similarly to the same GCC configuration, however with -O1 the code generated is actually slower, and the OSR version isn’t faster that a plain GCC -O1 configuration.
Let’s see how it works on bigger datasets, such as 300MB, focusing on the configurations with GCC:
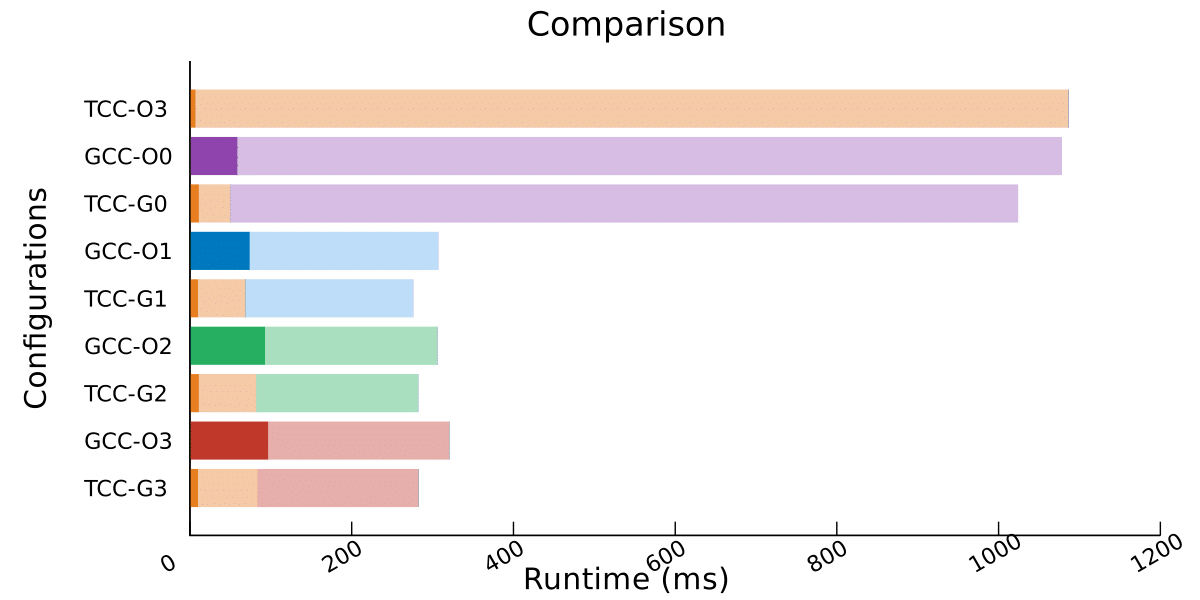
We observe a speedup of around 10% for each configuration!
We can see that the fastest execution is not always the most beneficial, for more information we invite you to look at the paper.