Since the beginning of development on Flare, the main focus has been on accelerating Spark SQL. But is Flare inherently restricted to Spark? Not at all.
Indeed, the Flare code base is made up of generic collections (e.g. Buffers, HashMaps, etc.) and Operators (e.g. Aggregates, Joins, Windows, etc.). The Spark-to-Flare compiler extracts the query plan generated by Spark’s query optimizer (called Catalyst) and creates a corresponding Flare operator plan.
A Spark query plan looks as follows:
Sort [l_returnflag#122 ASC NULLS FIRST, l_linestatus#123 ASC NULLS FIRST], true
+- Aggregate [l_returnflag#122, l_linestatus#123],
[l_returnflag#122, l_linestatus#123,
sum(l_quantity#118) AS sum_qty#374,
sum(l_extendedprice#119) AS sum_base_price#375,
sum((l_extendedprice#119 * (1.0 - l_discount#120))) AS sum_disc_price#376,
sum(((l_extendedprice#119 * (1.0 - l_discount#120)) * (1.0 + l_tax#121))) AS sum_charge#377,
avg(l_quantity#118) AS avg_qty#378,
avg(l_extendedprice#119) AS avg_price#379,
avg(l_discount#120) AS avg_disc#380,
count(1) AS count_order#381L]
+- Project [l_quantity#118, l_extendedprice#119, l_discount#120, l_tax#121, l_returnflag#122, l_linestatus#123]
+- Filter (l_shipdate#124 <= 10471)
+- LogicalRDD [l_orderkey#114, l_partkey#115, l_suppkey#116, l_linenumber#117, l_quantity#118, l_extendedprice#119, l_discount#120, l_tax#121, l_returnflag#122, l_linestatus#123, l_shipdate#124, l_commitdate#125, l_receiptdate#126, l_shipinstruct#127, l_shipmode#128, l_comment#129], false
What the Spark-to-Flare compiler does is create the corresponding Flare schemas and transform the Spark expressions to Flare expressions.
Therefore, it is possible to create an X-to-Flare compiler for any system that generates relational query plans with enough type information.
We now present our latest proof of concept: a Flink-to-Flare compiler!
While Spark has an internal query optimizer, Catalyst, Flink relies on Apache Calcite for this pupose. Thus, the only material difference between Spark-to-Flare and Flink-to-Flare is that the input query plan is not represented in Catalyst’s internal format, but in Calcite’s format.
Flink query plan:
== Optimized Logical Plan ==
DataSetSort(orderBy=[l_returnflag ASC, l_linestatus ASC])
DataSetAggregate(
groupBy=[l_returnflag, l_linestatus],
select=[l_returnflag, l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM($f4) AS sum_disc_price,
SUM($f5) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order])
DataSetCalc(
select=[l_returnflag, l_linestatus, l_quantity, l_extendedprice, *(l_extendedprice, -(1, l_discount)) AS $f4, *(*(l_extendedprice, -(1, l_discount)), +(1, l_tax)) AS $f5, l_discount],
where=[<=(l_shipdate, 1998-09-02)])
BatchTableSourceScan(
table=[[lineitem]],
fields=[l_returnflag, l_linestatus, l_quantity, l_extendedprice, l_discount, l_tax, l_shipdate],
source=[CsvTableSource(read fields: l_returnflag, l_linestatus, l_quantity, l_extendedprice, l_discount, l_tax, l_shipdate)])
Similar to Spark, the Flink query plan contains field/type information. Even if the operators are different - for example, Flink merges Project and Filters into a single node (see below) - the query plan representation is very similar. Indeed, this query plan is for the first query of TPC-H, and Flare accelerates Spark and Flink in the same way on that query.
Evaluation
We evaluated how Flare accelerates Flink on the full TPCH benchmark. The data is streamed from a CSV file. The performance of Flare is very similar whichever front-end system is used. However, Flink does not generate semi/anti-joins but uses equivalent aggregates on Boolean that are slightly slower (see Q18, Q22).
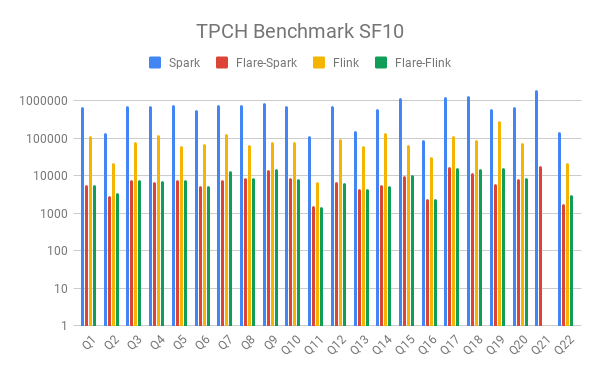
It is interesting to note that out of the box, and without any Flare acceleration, Flink is already quite a bit faster than Spark. However, Flare provides additional significant (read: order of magnitude) speedups.