We are glad to announce that Flare has been published in the proceedings of OSDI 2018. In this paper, we explain the different bottlenecks that keep Spark from achieving the best possible performance. We also explain the different solutions that we implemented in Flare in order to bypass the different issues discovered in Spark, and show that we are on par with the current state-of-the-art database management systems, while maintaining the Spark front-end.
One of the major bottlenecks is the data exchange between the code boundaries. Spark’s generation engine (Tungsten) generates multiple pieces of codes for the queries. These pieces of code follow an iterator interface with produce and consume methods. In profiling some queries, we can see that an important part of the execution is spent accessing and decoding the data representation or moving the data between those iterators’ interfaces through a precompiled runtime. Removing this runtime is of paramount importance in achieving good performance.
In addition, the code generation implemented by Tungsten has multiple issues, as it generates Java code using large templates. Also, because Spark was designed to be a cluster-computing framework, therefore the code generated is not optimized for single core machines.
Some Key Results
Flare displays similar performance as the state of the art in memory database system Hyper, and is orders of magnitude faster than Spark and Postgres. Running the TPC-H benchmark of a dataset of around 20GB:

We presented the result when scaling up Flare for SF100 with NUMA optimizations on different configurations: threads pinned to one, two, or four sockets. The speedups relative to a single thread are shown on top of the bars (Benchmark machine: 72 cores, 1 TB RAM across 4 CPU sockets,i.e., 18 cores, 250 GB each).
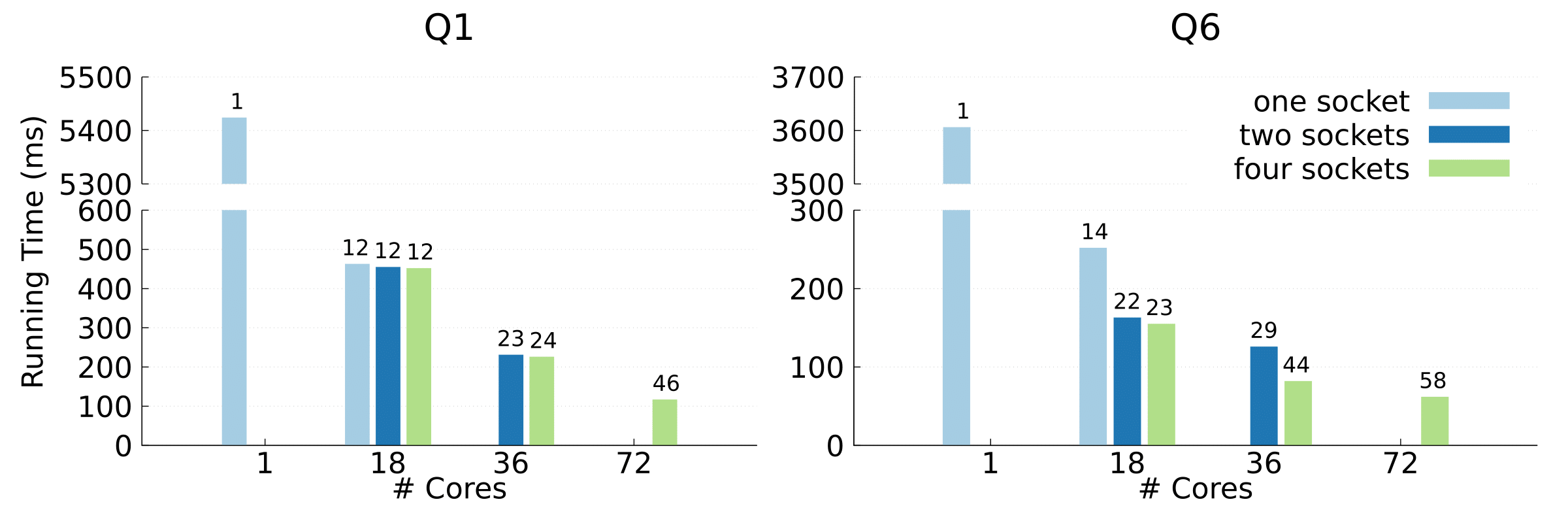
Talk
Check out our OSDI talk (audio only) and slides here!