This blog post summarizes part of our work that we published How to Architect a Query Compiler, Revisited. Ruby Tahboub, Grégory Essertel, Tiark Rompf. SIGMOD ‘18. For more details, we invite you to read the article!
We have demonstrated that Flare very efficiently accelerates Spark SQL’s DataFrame computation by extracting the plan generated by Spark and generating low-level code that computes the query. We also added support for data indexing, which is found in all good relational databases, however not currently supported by Spark itself. Data indexing is a technique that uses statistics and primary/foreign keys of input tables in order to create indexes that accelerate computations. These indexes can be seen as specialized data structures that make some operations more efficient; for example, a Join on a primary key can be compiled much more efficiently than a regular HashJoin by using the prexisting well-structured and well optimized index. Indeed, as indexes are precomputation, they can be implemented in a much more efficient way that a generic hash map.
Primary and foreign key indexes
Taking as example the table nation of the TPCH benchmark:
n_nationkey|.....
0|ALGERIA|0| haggle. carefully final deposits detect slyly agai|
1|ARGENTINA|1|al foxes promise slyly according to the regular accounts. bold requests alon|
2|BRAZIL|1|y alongside of the pending deposits. carefully special packages are about the i...
3|CANADA|1|eas hang ironic, silent packages. slyly regular packages are furiously over the...
4|EGYPT|4|y above the carefully unusual theodolites. final dugouts are quickly across the ...
5|ETHIOPIA|0|ven packages wake quickly. regu|
6|FRANCE|3|refully final requests. regular, ironi|
7|GERMANY|3|l platelets. regular accounts x-ray: unusual, regular acco|
8|INDIA|2|ss excuses cajole slyly across the packages. deposits print aroun|
9|INDONESIA|2| slyly express asymptotes. regular deposits haggle slyly. carefully ironic h...
10|IRAN|4|efully alongside of the slyly final dependencies. |
11|IRAQ|4|nic deposits boost atop the quickly final requests? quickly regula|
12|JAPAN|2|ously. final, express gifts cajole a|
13|JORDAN|4|ic deposits are blithely about the carefully regular pa|
14|KENYA|0| pending excuses haggle furiously deposits. pending, express pinto beans wake f...
15|MOROCCO|0|rns. blithely bold courts among the closely regular packages use furiously bo...
16|MOZAMBIQUE|0|s. ironic, unusual asymptotes wake blithely r|
17|PERU|1|platelets. blithely pending dependencies use fluffily across the even pinto bean...
18|CHINA|2|c dependencies. furiously express notornis sleep slyly regular accounts. ideas ...
19|ROMANIA|3|ular asymptotes are about the furious multipliers. express dependencies nag a...
20|SAUDI ARABIA|4|ts. silent requests haggle. closely express packages sleep across the bl...
21|VIETNAM|2|hely enticingly express accounts. even, final |
22|RUSSIA|3| requests against the platelets use never according to the quickly regular pin...
23|UNITED KINGDOM|3|eans boost carefully special requests. accounts are. carefull|
24|UNITED STATES|1|y final packages. slow foxes cajole quickly. quickly silent platelets b...
The n_nationkey attribute is a primary key, as we can see in line #i: n_nationkey == i. We can therefore create an index on that key. This optimization will make the following query much more efficient:
select * from nation, customer where n_nationkey == c_nationkey
Indeed, without realizing that n_nationkey is a primary key, Flare would generate a regular HashJoin, thus creating a MultiMap (allocation on multiple arrays) and populating it with a single tuple for each entry (adding some hashing, data duplication, and loss of locality). Using a primary key index on the left side of the Join, on the other hand, is practically a single array lookup!
As Spark does not support indexes in its query plan, we used the metadata field in the schema definition of the table in order to give Flare the necessary metadata information:
val schema_nation = StructType(Seq(
StructField("n_nationkey", IntegerType, metadata = metadata(primaryKey, dense, min(0), max(24))),
StructField("n_name", StringType, metadata = metadata(strDic(25))),
StructField("n_regionkey", IntegerType, metadata = metadata(foreignKey, dense, min(0), max(4), maxCard(5))),
StructField("n_comment", StringType)))
For the nation table, we can have additional information that can allow Flare to generate different indexes, such as a foreign key index. We can also add some extra statistics such as min, max, density, and cardinality. For example, a dense foreign key means that all values between the min (0) and the max (4) are present, and the cardinality specifies that at most 5 tuples in the table share the same value. Therefore, a 2D array of 5x5 is the most efficient and compact data structure that can be used to create an index on that key. In the case of sparse foreign keys, some sort of hash would have be used.
Flare also supports two other kinds of index: string dictionaries and date indexes.
String dictionaries
A string dictionary replaces a string with an integer. If we take as an example the part table of the TPCH benchmark, the attribute p_type can be one of 150 different strings, whereas the table is of size 200000. Thus, many values are repeated:
p_type
PROMO BRUSHED COPPER
PROMO PLATED BRASS
STANDARD POLISHED STEEL
ECONOMY BRUSHED TIN
SMALL ANODIZED STEEL
MEDIUM ANODIZED TIN
LARGE BURNISHED COPPER
PROMO BURNISHED STEEL
STANDARD POLISHED NICKEL
SMALL POLISHED COPPER
...
Instead of using the expensive string representation, each different value is transformed into an integer. This is a huge optimization when it comes to string operations, as string equality become a simple integer equality instead of an expensive loop. Even better, if the integers are assigned in a smart way (for example, by sorting the strings), operations such as compare or startsWith/endsWith can be optimized.
For example, taking the few string aboves and sorting them in an increasing order:
ECONOMY BRUSHED TIN 0
LARGE BURNISHED COPPER 1
MEDIUM ANODIZED TIN 2
PROMO BRUSHED COPPER 3
PROMO BURNISHED STEEL 4
PROMO PLATED BRASS 5
SMALL ANODIZED STEEL 6
SMALL POLISHED COPPER 7
STANDARD POLISHED STEEL 8
STANDARD POLISHED NICKEL 9
- x == “PROMO BRUSHED COPPER” ==> x == 3
- x like “PROMO%” ==> x >= 3 && x <=5
- x < “SMALL” ==> x < 5
For operations such as endsWith, the sorting needs to be based on the strings in an inverted order.
Date indexes
The date indexes partition the data per years, months, or days. It can therefore optimize filter or join operations on dates. The idea is very similar to primary/foreign key indexes.
Evaluation
We evaluated Flare on the the TPCH benchmark with different configurations. First without index, secondly with primary/foreign key indexes enabled, then adding the date indexes, and finally with the string dictionaries.
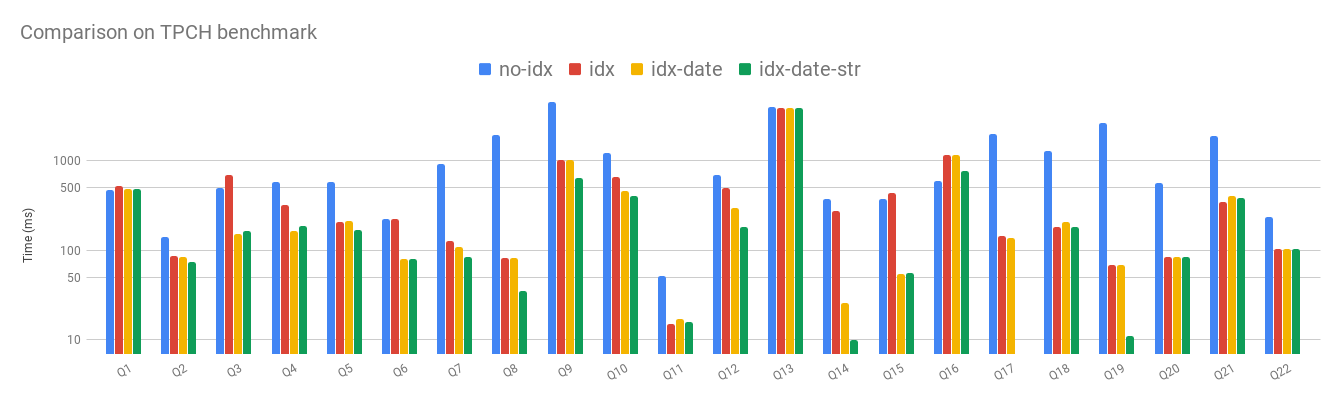
We note that in some queries, using the index is actually slower than the original hashmap. This is due to the fact that indexes are built on leaf nodes, whereas indexes are built on interior nodes with smaller intermediate results. As Flare does not perform a cost analysis, if indexes are enabled, it will try to use them even if it is not the optimal choice.