In our previous posts, we demonstrated Flare’s performance on a single core and on a scaled-up server-class machines. We showed order of magnitude speedups in the TPC-H benchmark.
In this blog post, we extend Flare further to accelerate heterogeneous workloads, consisting of relational queries combined with iterative machine learning kernels written as user-defined functions.
Heterogeneous Workloads
Flare’s native code translation alone already provides excellent performance for SQL queries and DataFrame operations. However, performance still suffers for heterogeneous workloads, e.g., when executing many small queries interleaved with user code, or when combining relational with iterative functional processing, as is common in machine learning pipelines.
While the Extract, transfer, and load part (ETL) of heterogeneous pipelines can often be implemented as DataFrames, the compute kernels often have to be supplied a user defined functions (UDFs), which appear as black boxes to the query optimizer, and thus remain as unoptimized library code.
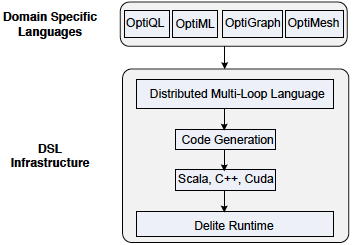
Delite: a compiler framework and runtime for parallel embedded domain-specific languages (DSLs)
Recently, there has been a notable interest in developing embedded DSLs to process data in heterogeneous parallel platforms as GPUs. DSLs are desirable for performance, productivity and portability. Delite model and compiler framework mitigates the burden of developing portable high performance DSLs. Delite’s front-end provides several Scala DSLs, covering various domains, e.g., databases, machine learning, linear algebra, etc. Since these DSLs are embedded in Scala, they provide user-facing APIs similar to libraries built on top of Spark.
The core of Delite is built around a first-order functional intermediate language called Distributed Multi-Loop Language (DMLL) that models parallel patterns. As the name suggests, DMLL represents parallel patterns as a highly flexible loop abstraction that fuses multiple loops to maximize pipeline and horizontal fusion. Furthermore, DMLL provides implicitly parallel and nested collection operations, e.g., Collect, Group by-Reduce, as well as optimizations like loop fusion, loop nesting optimizations, etc. Finally, DMLL generates optimized code for multiple hardware targets (e.g. NUMA, clusters, GPU, etc.)
User Defined Functions (UDF)
Spark SQL uses Scala functions which appear as a black box to the optimizer. Flare’s internal code generation logic is based on a technique called Lightweight Modular Staging (LMS), which uses a special type constructor Rep[T] to denote staged expressions of type T, that should become part of the generated code. Extending UDF support to Flare is achieved by injecting Rep[A] => Rep[B] functions into DataFrames in the same way as normal A => B functions in plain Spark. As an example, here is a UDF sqr that squares a given number:
// define and register UDF
def sqr(fc: FlareUDFContext) = { import fc._; (y: Rep[Int]) => y * y }
flare.udf.register("sqr", sqr)
// use UDF in query
val df = spark.sql("select ps_availqty from partsupp where sqr(ps_availqty) > 100")
flare(df).show()Notice that the definition of sqr uses an additional argument of type FlareUDFContext, from which we import overloaded operators such as +, -, *, etc., to work on Rep[Int] and other Rep[T] types. The staged function will become part of the code as well, and will be optimized along with the relational operations. This provides benefits for UDFs (general purpose code embedded in queries) and enables queries to be be optimized with respect to their surrounding code (e.g., queries run within a loop).
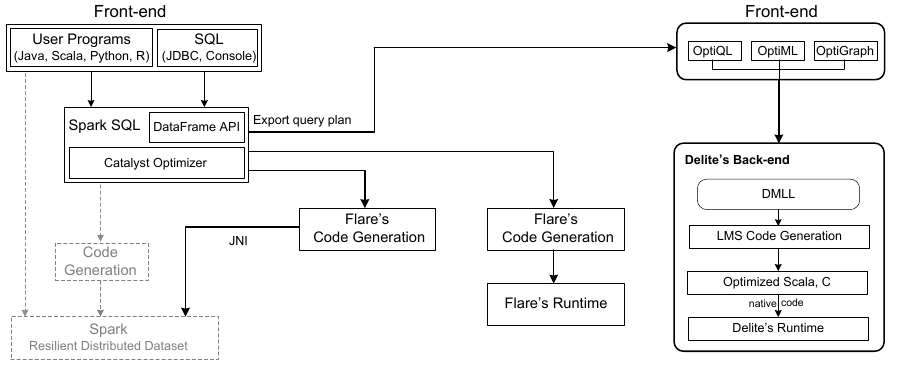
Flare Level 3
Flare Level 3 leverages Delite compiler framework, which is built on top of LMS, to efficiently compile applications that mix multiple DSLs or query languages. On the front-end, Flare Level 3 exports a Spark SQL optimized query plan and maps it to Delite’s OptiQL. Delites intermediate language DMLL analyzes user code with DSL and performs available optimizations e.g., loop fusion, loop nesting, etc. Finally Delite generates code for multiple hardware targets (e.g. NUMA, clusters, GPU, etc.)
The k-means Application
The k-means application partitions n data points into k clusters where each data point is assigned to the partition with the nearest mean. The following code snippet demonstrates the k-means application that mixes multiple DSLs, i.e., SQL and OptiML, with user code. In lines (6-8), Spark SQL reads data from a file and preprocesses input. Lines (10-24) show the k-means processing code using OptiML. Delite provides optimized data types (e.g., Vectors) and expressive libraries to assist ML computations. For instance, mapRowsToVector, dist, and untilconverged_withdiff are ML-specific optimized methods. The final result can be post-processed using SQL as illustrated in lines (26-27).
1 val tol = 0.001
2 val k = 4
3 def findNearestCluster(x_i: Rep[DenseVector[Double]],
4 mu: Rep[DenseMatrix[Double]]): Rep[Int] = {
(mu mapRowsToVector {
row => dist(x_i, row, SQUARE) }).minIndex}
5 /* Relational ETL */
6 val data = spark.read.csv[Data]("input")
7 val q = data.select(...)
8 val mat = flare(q).toMatrix
9 /* ML DSL with user code (k-Means training loop) */
10 val x = DenseTrainingSet(mat, DenseVector[Double]())
11 val m = x.numSamples
12 val n = x.numFeatures
13 val mu = (0::k, *) { i => x(randomInt(m)) }
14 val newMu = untilconverged_withdiff(mu, tol){ (mu, iter) =>
15 val c = (0::m) { e => findNearestCluster(x(e), mu) }
16 val allWP = (0::m).groupByReduce(i => c(i), i => x(i).Clone, (a: Rep[DenseVector[Double]], b: Rep[DenseVector[Double]]) => a + b)
17 val allP = (0::m).groupByReduce(i => c(i), i => 1, (a: Rep[Int], b: Rep[Int]) => a+b)
18 (0::k, *) { j =>
19 val weightedpoints = allWP(j)
20 val points = allP(j)
21 val d = if (points == 0) 1 else points
22 weightedpoints / d
23 }
24 }((x, y) => dist(x, y, SQUARE))
25 /* Relational and ML DSLs */
26 val r = spark.sql("""select ... from datawhere class = findNearestCluster(...) group by class""")
27 flare(r).show
Experiments
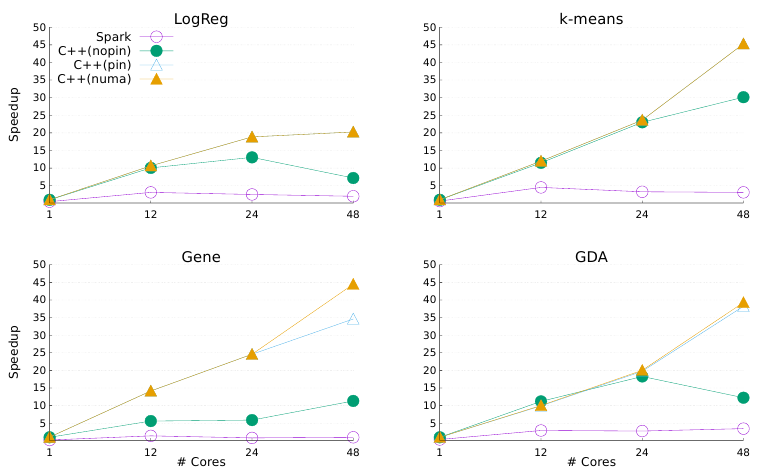
Shared-Memory NUMA
In a recent study, Brown et al. compared Spark with Delite with regards to NUMA scalability on a single shared-memory machine with 4 CPU sockets and a total of 48 cores. Specifically, Gaussian Discriminant Analysis (GDA), logistic regression (LogReg), k-means clustering, and a gene barcoding application (Gene) were chosen as machine learning benchmarks. As shown in the figure, Delite gains significant speedups over Spark in every application studied, with thread pinning and NUMA-aware data partitioning contributing in different ways for each application. As stated previously, Flare Level 3 generates code in Delite’s intermediate language DMLL, generates code that matches exactly the code in Brown et al.
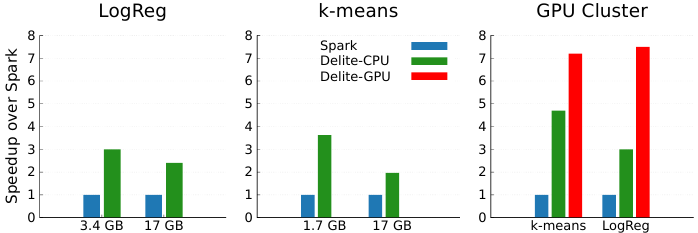
Brown et al also showcase speedups over Spark when running on a small cluster of machines, and when employing GPU accelerators on the k-means and LogReg applications. Despite running on Spark’s intended architecture, when run on Amazon EC2 using 20 nodes, the code generated by Delite demonstrated a 2x-3.5x speedup over Spark for k-means, and approximately a 2.5x-3x speedup for LogReg (as illustrated in the Figure below). When these applications were moved to a cluster of higher-end machines with more CPU cores as well as GPUs, this performance gap widened even further. The study shows that when running on a GPU cluster of 4 nodes, each with 12 cores, performance reaches more than 7x speedup for each application.