In our last post we looked at the performance of Spark vs hand-written C code for a single query, Q6, from the standard TPC-H benchmark. We saw that Flare is able to accelerate the Spark query by a factor of 20x, to exactly the same performance as the hand-written C program.
In this post, without further ado, we present results for the full TPC-H suite of 22 queries. We are again interested in single core performance, mainly to gauge the inherent overheads in Spark, which Flare reduces by a large margin.
Why single-core? Quoting Paul Barham via Frank McSherry: “You can have a second computer once you’ve shown you know how to use the first one”. Premature scale-out has immediate drawbacks in terms of higher datacenter and operating costs, and inefficient use of energy may have consequences as far-reaching as contributing to global warning.
All numbers below are in milliseconds (ms), measured on a single core, after pre-loading the data into memory. We show results first for the SF1 dataset (1 GB), then for SF10 (10 GB).

| SF1 | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | Q16 | Q17 | Q18 | Q19 | Q20 | Q21 | Q22 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PostgreSQL | 24289 | 680 | 3422 | 833 | 1163 | 2534 | 1725 | 2599 | 6030 | 3433 | 672 | 3932 | 2362 | 2445 | 2416 | 1353 | 11712 | 8916 | 3121 | 6580 | 4071 | 1163 |
| Spark SQL | 3539 | 10640 | 7803 | 5433 | 35243 | 675 | 10756 | 4473 | 24171 | 18222 | 8355 | 4621 | 6102 | 905 | 3744 | 16534 | 5099 | 7031 | 2458 | 7451 | 21903 | 3911 |
| Flare | 42 | 16 | 63 | 52 | 51 | 19 | 59 | 98 | 251 | 142 | 12 | 93 | 225 | 29 | 32 | 174 | 1042 | 89 | 433 | 78 | 280 | 62 |
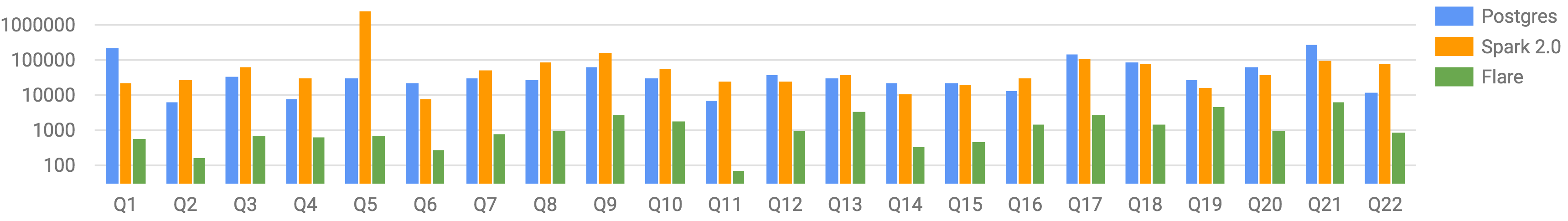
| SF10 | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | Q16 | Q17 | Q18 | Q19 | Q20 | Q21 | Q22 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PostgreSQL | 241404 | 6649 | 33721 | 7936 | 30043 | 23358 | 32501 | 29759 | 64224 | 33145 | 7093 | 37880 | 31242 | 22058 | 23133 | 13232 | 155449 | 90949 | 29452 | 65541 | 299178 | 11703 |
| Spark SQL | 22487 | 29387 | 66502 | 30168 | 2554893 | 8463 | 51715 | 91718 | 175146 | 60688 | 26560 | 25701 | 39432 | 10942 | 21552 | 31349 | 109502 | 81018 | 16384 | 38774 | 95982 | 85351 |
| Flare | 616 | 166 | 723 | 638 | 744 | 285 | 846 | 1053 | 2963 | 1856 | 73 | 999 | 3620 | 355 | 486 | 1549 | 2928 | 1473 | 4967 | 1012 | 6679 | 887 |
We can see that Flare exhibits large speedups, not only compared to plain Spark, but also to widely used relational database systems like PostgreSQL.
What does this mean for scalability? By using each individual core much more efficiently, Flare can process data at much lower cost. For some queries, we would have to run Spark on hundreds of cores, quite likely spread across a cluster of tens of machines – and with perfect scalability – to achieve the same performance as Flare on a single core.
Now what about parallel performance in Flare? That’ll be a topic for another post.