In our previous posts, we looked at Spark performance with and without Flare for the TPC-H suite of 22 queries. We were mainly interested in single core performance, to gauge the inherent overheads in Spark, and we showed that Flare can reduce those by one or even two orders of magnitude.
But of course, once we obtain good performance on a single core, we want to scale.
Our focus in Flare is on scala-up performance on server-class machines. Such machines usually contain multiple CPU sockets, each of which is attached to a separate chunk of memory. Thus, memory access characteristics are non-uniform (NUMA), and non-local memory accesses come with a steep overhead which may kill scaling altogether. Thus, care must be taken to optimize the internal data layout and memory access patterns accordingly.
We present Flare results for two queries below (TPCH Q1 and Q6). Our benchmark machine has 4 CPU sockets with a total of 72 cores, and 1 TB of main memory, with 256 GB attached to each CPU socket.
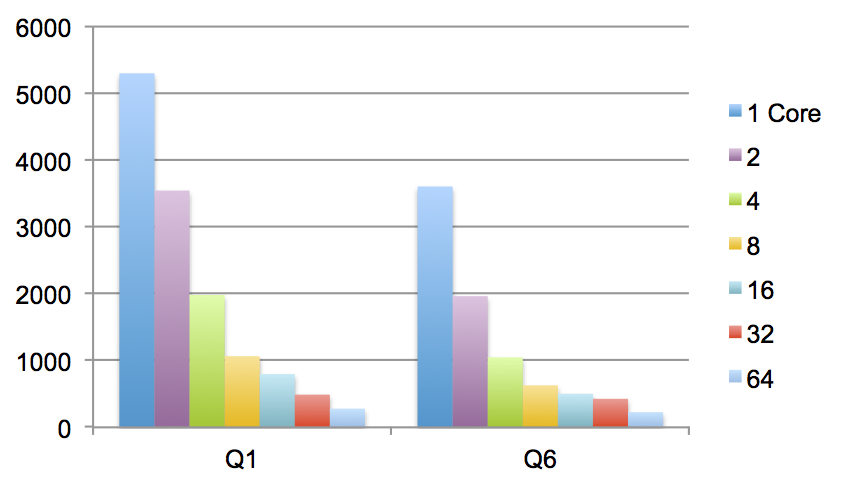
| Query | 1 | 2 | 4 | 8 | 16 | 32 | 64 | Cores |
|---|---|---|---|---|---|---|---|---|
| Q1 | 5300 | 3545 | 1981 | 1065 | 797 | 490 | 279 | |
| Q6 | 3606 | 1964 | 1047 | 629 | 503 | 427 | 227 |
So, here we have a single machine processing a dataset of roughly 80 GB in about 250 ms.
What is especially important is that we keep scaling across multiple CPU sockets and memory regions: the results for 32 and 64 cores involve 2 and 4 sockets respectively.
Note that we are comparing to a highly optimized sequential implementation, which has no provisions for parallelism, and can therefore use more efficient internal data structures in a few cases. Thus, we could not expect to see completely linear speedups.